GAMES101
我的图形学启蒙,世界上最好的图形学教程之一 !
MVP(model-view-projection)
齐次坐标(Homogenous Coordinates)
- \(3D\ point=(x,y,z,1)^T\)
- \(3D\ vector=(x,y,z,0)^T\)
- \((x,y,z,w)^T=(x/w,y/w,z/w,1)^T\)
目的是让Translate操作与rotation/scale等操作不割裂
- Think about how to take a photo
- Find a good place and arrange people(model transformation)
- Find a good "angle" to put the camera(view transformation)
- Cheese!(projection transformation)
model
将对象从局部坐标系(对象坐标系)变换到世界坐标系
简单通俗来讲,就是将场景中的模型摆好,这个过程就叫模型变换。模型变换不同顺序有不同的结果,其实就是因为矩阵相乘不满足交换律,但满足结合律,所以对应同一个复合变换,可以先得出其中的基础变换的矩阵乘积,再与输入向量相乘。一般地,先进行线性变换,再进行非线性变换。模型变换有如下所列形式:
- 缩放(Scale)

- 错切(shear)

- 旋转(Rotation)
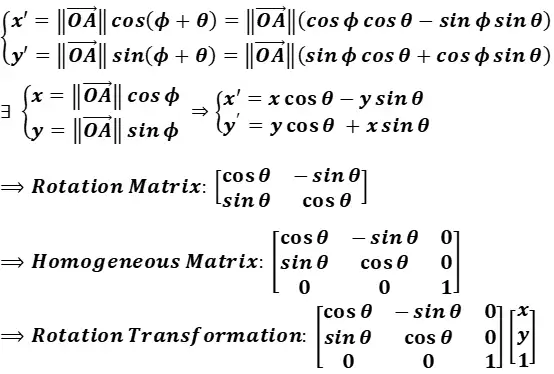
- 平移(Translation)

view
- Define the camera first
- Position (相机的位置)
- Look-at / gaze direction (相机的朝向)
- Up direction (相机倾斜的角度)
假设你正在一辆火车上拍照,车厢和你同时运动,你拍出来的照片是一样的,这就说明了相机拍出来的画面是相对的
- 我们可以约定俗成地将相机放在\((0,0,0)\)的位置上,并且让相机的朝向\(-z\)方向, up at \(y\),同时transform the objects along with the camera.
为了实现这一构想,我们需要将相机先平移到原点,再旋转到正确的方向
\(\(M_{view} = R_{view}T_{view}\)\)

-
summary
-
由于我们将相机和物体同时应用相同的变换,物体也会位于正确的位置上
-
模型变换和视图变换的结果是将三维世界transfer into 相机系下,它们通常被合称为模型视图变换
- 下一步就是应用projection transformation将相机坐标系(3维)下的对象转换到屏幕坐标(2维)上
projection
- 分为两种:正交投影(Orthographic projection)和透视投影(Perspective projection),透视投影会近大远小,而正交投影不会
正交投影可以看成是相机位置无限远的透视投影
Orthographic Projection
将一个空间中的立方体(自己规定的要作用的范围)的中心先平移到原点再缩放到一个2*2*2的一个正方体中,在次之后将要应用视口变换
Perspective Projection
即先做一个透视到正交的矩阵,再应用正交变换
推导:
设\(M_{persp\rightarrow ortho }=\begin{bmatrix} n & 0 & 0 &0 \\ 0 & n & 0 &0 \\ ? & ? & ? & ?\\ 0 & 0 & 1 &0 \end{bmatrix}\)
\(M_{persp\rightarrow ortho }(x,y,z,1)^T=(nx,ny,unkown,z)^T\)
由于任何近平面上的物体都不会改变
故令\(z=n\)则\(M_{persp\rightarrow ortho }(x,y,n,1)^T=(x,y,n,1)=(nx,ny,n^2,n)^T\)
则\(M_{persp\rightarrow ortho }\)第三行为\((0,0,A,B)\)且\(\begin{pmatrix} 0 & 0 & A &B \end{pmatrix}\begin{pmatrix} x \\ y \\ n \\ 1 \end{pmatrix}=n^2\)
可知:\(An+B=n^2\)
又因为远平面上中心点\((0,0,f,1)\)不变
可知:\(\begin{pmatrix} n & 0 & 0 &0 \\ 0 & n & 0 &0 \\ 0 & 0 & A & B\\ 0 & 0 & 1 &0 \end{pmatrix}\begin{pmatrix} 0 \\ 0 \\ f\\ 1 \end{pmatrix}=\begin{pmatrix} 0 \\ 0\\ Af+b\\ f \end{pmatrix}= \begin{pmatrix} 0 \\ 0\\ f^2\\ f \end{pmatrix}\Rightarrow Af+B=f^2\)
解得:\(A=n+f,B=-nf\)
即\(M_{persp\rightarrow ortho }=\begin{bmatrix} n & 0 & 0 &0 \\ 0 & n & 0 &0 \\ 0 & 0 & n+f & -nf\\ 0 & 0 & 1 &0 \end{bmatrix}\)
- A interesting question: what if \(z = \frac{n+f}{2}\)? will it be near or far?
光栅化(Rasterize)
对象经过MVP变化后,需要进行光栅化,即将上一步得到的立方体投射到屏幕空间
屏幕空间的基本单位:像素
-
视口变换(viewport):
-
Irrelevant to z
-
Transform in xy plane: \([-1,1]^2\) to \([0,width]\times[0,height]\)
-
Viewport transform matrix:
\[M_{viewport}=\begin{pmatrix} \frac{width}{2} & 0 & 0 & \frac{width}{2} \\ 0 & \frac{height}{2} & 0 &\frac{height}{2} \\ 0 & 0 & 1 & 0\\ 0& 0 & 0 &1 \end{pmatrix}\] -
采样:利用像素中心得到像素的属性
-
如果采样率相对于像素来讲不够高,则会发生走样(Aliasing),具体表现为锯齿(Jaggies)

-
判断点是否在三角形内部,\(P_1P_2\times P_1Q\) 的正负可以反映点Q在边P1P2的左侧或是右侧,三条边都应用上述操作即可知道
叉乘:
\[a \times b=\left|\begin{array}{lll} \mathrm{i} & \mathrm{j} & \mathrm{k} \\ x_{1} & y_{1} & z_{1} \\ x_{2} & y_{2} & z_{2} \end{array}\right|=\left(y_{1} z_{2}-y_{2} z_{1}\right) i+\left(z_{1} x_{2}-z_{2} x_{1}\right) j+\left(x_{1} y_{2}-x_{2} y_{1}\right) k\]
- Bounding box:包围盒,只有包围盒里的像素才需要光栅化,包围盒之外的像素太远了!
反走样&深度缓存(Anti-Aliasing & z-buffer)
反走样
-
采样出现瑕疵(artifacts)的原因是采样的频率跟不上信号的频率
-
Anti-Aliasing:
- Pre-filter:对原始信号进行一个模糊(滤波)(卷积)
-
提高采样率(reduce aliasing error not anti-aliasing)
-
卷积:

-
MSAA(多重采样反走样 Multisample anti aliasing)
-
把像素内部分为\(N\times N\)个点, 判断这些点有多少个是位于三角形内的, 根据比例为该像素着色
- Average the \(N\times N\) samples "inside" each pixel.是一种"模糊"的方法
- What's the cost of MSAA:增加了计算量,理论上会增加\(N\times N\)计算量,实际上工业界会取点并不会这么规则,实际上不会增加如此大的计算量
SSAA(超采样反走样 Super Sampling Anti Aliasing)
MSAA是SSAA的优化, MSAA与SSAA的区别在于像素着色器(Pixel Shader)的运行次数。
-
超分辨率:
-
本质上是在光栅化之后的结果图应用, 一般用于屏幕分辨率太高而图像分辨率较低, 通过"猜"的方式来提高分辨率, 而进行"猜"最好的方式就是深度学习, 于是有了DLSS
- From low resolution to high resolution
- Essentially still "not enough samples" problem
- DLSS(Deep Learning Super Sampling)
深度缓存
-
画家算法: overwrite
-
两个缓冲: frame-buffer/depth-buffer
-
z-buffer Algorithm
```pseudocode Initialize depth buffer to infinity
During rasterization:
for(each triangle T) for(each sample (x,y,z) in T) if(z < zbuffer[x,y]) //closest sample so far framebuffer[x,y] = rgb; //update color zbuffer[x,y] = z; //update depth else ; //do nothing, this sample is occluded ```
z-buffer 处理不了透明物体!
着色(shading)
Definition:对不同物体应用不同的材质(Texture)
Blinn-Phong Reflectance Model(布林冯反射模型)

布林-冯反射模型规定,物体具有三种反射:高光(Specular highlights)、漫反射(Diffuse reflection)、环境光(Ambient lighting)

这里注意,着色≠阴影,如下图我们只考虑了物体的明暗关系并没有考虑物体产生的阴影。阴影会有专门的过程进行处理。
高光&漫反射
高光:
-
我们只可以从镜面方向看到,引入半程向量:即当半程向量与法线方向很接近,也可以看到高光
-
半程向量h: \(\mathbf{h}=\operatorname{bisector}(\mathbf{v}, \mathbf{l})=\frac{\mathbf{v}+\mathbf{l}}{\|\mathbf{v}+\mathbf{l}\|}\)(I为入射方向向量,V为反射方向向量)
-
\(L_s=k_s(I/r^2)max(0,cos\alpha)^p=k_s(I/r^2)max(0,n\cdot h)^p\)
-
其中\(k_s\)是镜面反射系数,通常为白色。对于镜面反射布林-冯反射模型不考虑镜面反射的点吸收了多少能量。我们还注意到,在反应\(n,h\)夹角的时候我们加入了一个指数\(p\)。这是因为余弦值对于两个向量之间夹角的大小“容忍度”太大,如下图最左边所示,当$ \alpha=45°\(的时候cos还是有较大的值。如果我们单单使用余弦值来表示半程向量\) \bold{h}\(与法线方向\)\bold{n}\(的接近程度的话,那我们将会得到很大一片高光(\)30°\(甚至\)40°\(时仍会看到高光)。所以我们加入一个指数\)p\(,可以看出,当\) p=64\(时(最右侧图)\) \cos20°$已经是很小的值了。

漫反射:
-
在布林-冯反射模型中,漫反射表示,当光照在物体上,物体会将光线反射到四面八方去。但是,当物体与光照角度发生变化时物体表面的阴影关系会发生变化。如果我们将光看做是一种能量,那么物体表面法线和光照方向的角度越大则物体单位面积接收到的能量就越少,也就是说物体表面将看起来更暗。这就是兰伯特余弦法则(Lambert’s cosine law),用公式表达为$ \cos \theta=\bold{I}\cdot\bold{n}\(越大(即角度\)\theta$越小)物体单位面积接收到的能量就越大。
-
由于光在传播过程中会有能量损失,我们规定某一点光源在半径\(r\)处的能量为$ I/r^2\(,其中\)I$为点光源在自身处的能量。现在有了光源到物体某一点的总能量值和物体接收到的能量,那么我们就可以计算漫反射的亮度了
$$ L_d=k_d(I/r^2)\max(0,\bold{n}\cdot\bold{I})$$
式中$ k_d
\(是漫反射系数(颜色),\) I/r^2\(是到达某一点的能量,\) \max(0,\bold{n}\cdot\bold{I})$表示物体接收了多少能量。由于漫反射是物体向四面八方反射光线的,所以无论我们在哪个角度去观察他得到的结果都是一样的。

这里参考了博客:(16条消息) 现代计算机图形学笔记(五)——深度测试、着色_图形学深度测试_Feyily的博客-CSDN博客
着色频率
逐面(flat shading): 对每个面求法线, 进行着色
逐顶点(Gouraud shading): 对每个三角形的顶点求法线, 三角形内部通过差值的方式着色
把顶点周围的所有面的法线求平均即是顶点的法线
逐像素(Phong shading): 对法线值做插值,对每个点做Shading
shadow mapping
光栅化下对全局光线传输、阴影的处理十分麻烦。
- draw shadows using rasterization
- An Image-space Algorithm
- 不需要场景的几何信息
- 有走样现象
- 思想:the points NOT in shadow must be seen both by the light and by the camera
步骤:
- Pass 1: Render from Light
- Depth image from light source → shadow map
- Pass 2A: Render from Eye
- Standard image (with depth) from eye
- Pass 2B: Project to light
- Project visible points in eye view back to light source
- visible to light source → color
- blocked → shadow
感觉每个光源对每个静态场景有一个shadow map
应用:
- 几乎所有3D游戏
问题:
-
走样、分辨率
-
数值精度问题
-
Involves equality comparison of floating point depth values means issues of scale, bias, tolerance
-
只能点光源、硬阴影
纹理(texture)
- uv: uv都在0~1之间
- 设计纹理时最好能上下左右无缝衔接
纹理太小怎么办→插值
- 多个pixel映射到了同一个texel
- 解决:
- Nearest
-
Bilinear
- Bilinear 插值 lerp
- 水平+竖直插值→双线性插值
- 最近的四个点插值
-
Bicubic 双向三次插值
- 周围16个点做三次插值
- 运算量更大,结果更好
纹理太大怎么办
-
一个pixel对应了多个texel, 采样频率不足, 导致摩尔纹和锯齿
-
解决:
-
Supersampling
- 太浪费!
- Just need to get the average value within a range
- Point Query vs. (Avg.) Range Query
- Mipmap:Allowing (fast, approx., square) range queries
- 每一次长宽各减半 D=0,1,2,...
- “Mip hierarchy”
- overhead: 1/3
- 怎么知道层数D?约为相邻pixel的映射uv之间的距离取2的对数
- 如果计算出来需要的D是整数,就很方便
- 如果计算出来需要的D不是整数→Trilinear Interpolation三线性插值
- 分别在floor(D)和ceil(D)上做Bilinear Interpolation取颜色值之后再插值
- Limitation:Overblur
- 不是方块查询
- Solution:各向异性过滤
- 各向异性过滤Anisotropic Filtering
- Ripmaps and summed area tables
- Can look up axis-aligned rectangular zones
- 长/宽/长和宽 各减半
- EWA filtering 椭圆取样
- 利用多次查询求平均值的方法来处理不规则区域
- overhead:3
- 多少x:压缩到多少x,显存足够的情况下开越高越好
像素覆盖的区域大小各不相同
Application of Texture
各种贴图
texture = memory + range query (filtering)
- General method to bring data to fragment calculations
Many applications
-
Environment lighting - Environment Map
-
环境光贴图
- 例子:Utah Teapot
- 经典:Stanford Bunny,Cornell Box
- Spherical Environment Map
- 球心:世界中心
- 一个问题:拉伸,想象地球仪展开
- 解决方法:Cube Map
-
Cube Map:立方体表面,从球心到球面的投影向外
- 扭曲更少,但是Need dir->face computation,计算量更大
-
Store microgeometry
-
Textures can affect shading! → define height/normal → Bump / Normal Map
- 两者类似,都可以以假乱真
- 改变表面的法线
-
Bump Mapping 凹凸贴图
Bump Mapping的Texture记录了高度移动
- 不改变几何信息
- 逐像素扰动法线方向
- 高度 offset 相对变化,从而改变法线方向
- 计算法线方向:切线的垂直方向
-
Displacement mapping 位移贴图
- 输入相同(Texture与Bump Mapping可共用)
- 改变几何信息,对顶点做位移
- 相比上更逼真,要求模型足够细致,运算量更高
- DirectX有Dynamic的插值法,对模型做插值,使得初始不用过于细致
-
Procedural textures
-
3D Procedural Noise + Solid Modeling
- 定义空间中任意点的颜色
- 噪声+映射→
- Perlin Noise
-
Provide Precomputed Shading
-
Ambient occlusion texture map
- 计算好的环境光遮蔽贴图
- 空间换时间
-
Solid modeling & Volume rendering
-
三维渲染
Shadow mapping
光栅化下对全局光线传输、阴影的处理十分麻烦。
- draw shadows using rasterization
- An Image-space Algorithm
- 不需要场景的几何信息
- 有走样现象
- 思想:the points NOT in shadow must be seen both by the light and by the camera
步骤:
- Pass 1: Render from Light
- Depth image from light source → shadow map
- Pass 2A: Render from Eye
- Standard image (with depth) from eye
- Pass 2B: Project to light
- Project visible points in eye view back to light source
- visible to light source → color
- blocked → shadow
感觉每个光源对每个静态场景有一个shadow map
应用:
- 几乎所有3D游戏
问题:
- 走样、分辨率
- 数值精度问题
- Involves equality comparison of floating point depth values means issues of scale, bias, tolerance
- 只能点光源、硬阴影
shading 和 texture 的作业参考了(深度解析)GAMES 101 作业3:渲染小奶牛 - 知乎 (zhihu.com)
插值
对于三角形ABC, 有: \(\(重心(x,y)=\alpha A+\beta B+\gamma C,\ \alpha+\beta+\gamma=1\)\)
我们称\((\alpha, \beta,\gamma)\)为重心坐标
由数学推导可知:


几何(Geometry)
Many ways to represent geometry
Implicit(隐式)
- example: sphere: all points in 3D, where \(x^2+y^2+z^2=1\)
-
more generally: f(x,y,z) = 0
-

-
距离函数(distance function)
-
SDF(signed distance field)

-
level sets(水平集)
-
Fractals(分形)
Explicit(显式)
- point cloud
-
有很多研究做如何把点云转化为三角形等
-
polygon mesh(*用的最多)
-
store 三角形或者多边形(一般是三角形和四边形)
-
更复杂的数据结构
-
例子:hw3中
.obj格式文件
-
subdivision, NURBS
-
example: 映射: \((u,v)\rightarrow (x,y,z)\) 如 \(f(u,v)=(\cos u\sin u,\sin u\sin v,\cos v)\)
曲线和曲面(curves and surfaces)
贝塞尔曲线


举例:
assume \(n = 3\)
\[b_0=(0,2,3),b_1=(2,3,5),b_2=(6,7,9), b_3=(3,4,5)\]These points define a Bezier curve in 3D that is a cubic polynomial in :
\[b^n(t)=b_0(1-t)^3+b_13t(1-t)^2+b_23t^2(1-t)+b_3t^3\]
性质:
- Interpolates(插值) endpoints
- For cubic Bezier: \(b(0) = b_0;b(1)=b_3\)
- Tangent to end segments(切线)
-
Cubic case: \(b'(0)=3(b_1-b_0);\ b'(1)= 3(b_3-b_2)\)
-
Affine(仿射) transformation property
-
Transform curve by transforming control points
-
Convex hull(凸包) property
- Curve is within convex hull of control points
But!贝塞尔曲线在点很多的时候效果不好(每个点都会对整体产生影响)
此时可以逐段进行贝塞尔,即: Piecewise Bezier Curve
other types of splines
- Spline
- B-splines(及其复杂, 在此不做展开)
- NURBS
贝塞尔曲面
先水平方向生成贝塞尔曲线,再竖直方向利用刚刚的曲线上的点生成贝塞尔曲线
Mesh(三角面片)
Mesh Subdivision(曲面细分)

- Loop Subvision
- Split each triangle into four
-
Assign new vertex positions according to weights
-
Catmull-Clark Subdivision(General Mesh)
-
Non-quad face:非四边的面
-
Extraordinary vertex (奇异点):指(degree != 4)的点
-
Each subdivision step:
-
Add vertex in each face
-
Add midpoint on each edge
-
Connect all new vertices
-





Mesh Simplification(曲面简化)
- 一种方法: 边坍缩(edge collapsing)
Edge Collapse:边坍缩
- 哪些边坍缩?如何坍缩?
- Quadric Error Metrics(⼆次误差度量)放在二次误差之和最小的地方
Simplification via Quadric Error
- iteratively collapse edge with smallest score
- 有问题,一条边的操作会影响其它边,需要更新
- 数据结构:优先队列 or 堆
- 贪心算法,非全局最优
- 可以有的放矢
光线追踪(Ray Tracing)
光栅化不能解决全局的问题, 如
- 软阴影
- 毛玻璃
-
间接光照
-
光线追踪的问题: 慢, 一帧需要10K的CPU小时(hour)
-
光线追踪的优势: 质量高
Light Rays(光线的性质)
- 光沿直线传播
- 光线不会碰撞
- 光路可逆*
光线追踪的基本过程
- 对于每个像素, 从眼睛投出去一个光线, 与场景中的物体相交找到交点
- 从交点出发向光源连线判断是否可见
- 算着色并写回像素
最古老的光线追踪方法: Whitted-Style
- 本质是一种递归的方法
- 我们知道, 当光线遇到玻璃的时候, 会有一部分光线反射, 一部分光线折射
-
这样一条从眼睛投射出去的光线就会与场景中的物体产生许多交点, 我们将每个交点都与光源连线判断是否可见, 如果可见, 则计算着色并加权写入像素
-
从眼睛出去的光线叫做primary ray, 其他的叫做secondary rays, 交点与光源之间的连线叫做shadow rays

如何判断光线与物体的相交
判断一个点是否在一个物体内部
从点向外部发出射线, 只要是在物体内部, 一定会与物体有奇数个交点
判断光线是否与三角形相交
可以拆成两部分:
- 光线是否与三角形所在的平面相交
- 利用光栅化的思想, 判断这个交点是否在三角形内部
判断光线是否与平面相交
-
首先我们要知道, 光线在图形学中可以简单地用向量来表示:\(r(t)=o+td\), 其中o表示光线的出发点, d表示光线的方向, r表示光线在t时刻的位置
-
那么, 如何表示一个平面呢? 我们可以用一条法线\(N\)和一个点\(p'\)来表示
- 那么如何确定一个点\(p\)是否在平面上呢? 只需要满足\((p-p')\cdot N=0\)即可
因此, 我们联立解方程:
-
Set \(p=r(t)\) and solve for t
-
\((p-p')\cdot N=(p+td-p')\cdot N=0\)
- \(t=\frac{(p'-o)\cdot N}{d\cdot N}\)
- Check: \(0 \leq t \leq \infin\)
除了上述方法, 我们还可以使用MT算法:

如何*加速*光线和表面的求交操作
包围体积(Bounding Volumes)
- AABB(Axis-Aligned Box), 用一个平行于xyz轴的立方体包住(并不是每个物体有一个包围盒, 而是一个物体会占据哪些包围盒)
- 六个面最晚的进入时间是\(t_{enter}(可以为负)\), 最早的退出时间\(t_{exit}\)
- ray和AABB相交当且仅当\(t_{enter}<t_{exit}\) && \(t_{exit}\ge0\)
- 场景被均等划分为若干个格子, 光线依次经过每个盒子时检测盒子内是否有物体, 我们假设检验光线是否与盒子相交的速度远快于检验光线是否与物体相交
- 关于场景中应该放多少包围盒是一个玄学(经验模型)
我承认阁下AABB加速很强, 但是假如我操场上只放一个茶壶(Teaport in the stadium), 不知阁下又该如何应对?
空间划分(Spatial Partitions)
物体分布稀疏的地方应该用更少的格子, 同理物体分布密集的地方需要更多的盒子
八叉树 (Oct-Tree)
将一个立方体三个方向各来一刀切成八块, 同理在二维空间是四叉树, 在一维空间是二叉树, 但是在更高维时开支太大, 因此我们引入KD-Tree
KD-Tree
永远是沿某一个轴(面)将其砍成两个


物体划分(Object Partitions) & Bounding Volume Hierachy(BVH)
- 得到了非常广泛的应用
- 对于划分也很有讲究


具体步骤:
- 找到包围盒
- 递归地将包围盒中的物体分成两部分
- 怎么划分?
- 选择合适的轴(x or y or z)划分
- 总是选择最长的轴进行划分
- 选择中间物体所在的位置进行划分
- 怎么找中间物体: 快速选择算法(\(O(N)\))[力扣215] 快速选择算法&划分树 - 知乎 (zhihu.com)
- 给这两部分分别计算新的包围盒
- 当节点中有足够少的三角形时停止递归
- 在叶子节点里记录下实际的物体
Intersect(Ray ray, BVH node)
{
if (ray misses node.bbox) return;
if (node is a leaf node)
test intersection with all objs;
return closest intersection;
hit1 = Intersect(ray, node.child1);
hit2 = Intersect(ray, node.child2);
return the closer of hit1, hit2;
}
辐射度量学(Basic radiometry)
为什么要学Radiometry
- 如之前在作业3里面有
Light intensity = 10,10是什么? - 布林冯模型是不真实的, Whitted style也是不真实的
- 辐射度量学就是要真实
什么是Radiometry
- Measurement system and units for illumination
- Accurately measure the spatial properties of light
- New terms: Radiant flux, intensity, irradiance, radiance
- Perform lighting calculations in a physically correct manner
名词解释
Radiant Energy and Flux(Power)

- 大概, Energy是能量, Flux是功率(通量?)
Radiant Intensity
- power per unit solid angle

什么是立体角: 弧度制在三维空间的延伸


辐射照度(Irradiance)
类似于通量的概念,平方衰减

辐射率(Radiance)
定义: 每单位立体角每单位投影面积的能量

Recall
- Irradiance: 每单位投影面积的能量
- intensity: 每单位立体角的能量
so
- Radiance: 每单位立体角的Irradiance
- Radiance: 每单位投影面积的Intensity
Radiance无非就是在Irradiance的基础加了一个方向性
Irradiance就是对各个方向的Radiance的积分
我们希望有一个函数能够定义一个点能向不同的点反射多少能量
从各个方向接收到的irradiance, 反射到某一个方向的radiance上去
双向反射分布函数(BRDF)
通俗定义: 微小面积\(dA\)从某一个微小立体角\(d\omega_i\)接收到的irradiance会反射多少radiance到各个不同的立体角上去

反射方程
后面三项\(L_i(p,\omega_i)\cos\theta_id\omega_i\)积分的可以看出是单位面积dA中收到的所有irradiance

渲染方程
整个场景不止一束光线, 光线反射出来还会不断反射, 是一个递归的过程
且有些物体不仅可以反射光线, 自己本身也可以发光
其中\((n\cdot \omega_i)=\cos\theta_i\)

蒙特卡洛积分(Monte Carlo integration)
一个用来求定积分的方法, 不关心函数的解析式是如何的, 只需要能算出积分的结果即可
基本思想: 在积分域上随机取样, 把整个积分域当成是一个长方形计算出积分结果, 把所有取样的积分结果求平均
其中p(x)是pdf(概率密度函数)
好处是不用管积分域了, 因为概率密度函数就限定了积分域
渲染方程两大难点:
- 积分的计算\(\rightarrow\)蒙特卡洛积分
- 递归的计算
引进蒙特卡洛积分之后, 渲染方程为约等于:
故可作伪代码:
(只考虑非光源)
shade(p, wo)
Randomly choose N direction wi~pdf
Lo = 0.0
For each wi
Trace a ray r(p, wi)
If ray r hit the light
Lo += (1 / N) * L_i * f_r * cosine / pdf(wi)
Else If ray r hit an object at q
Lo += (1 / N) * shade(q, -wi) * f_r * cosine / pdf(wi)
Return Lo
但此方法有两个很严重的弊端
- 光线数量爆炸: 它的开销是N的指数级增长, 我们想要让他不是指数级增长, 我们可以让N=1, 这就是路径追踪的思想
- 停不下来: 俄罗斯轮盘赌
路径追踪
路径追踪由于N=1, 生成的图片总是很noisy, 虽然规定了光反射的光束为1条, 但是pixel可以向不同方向发出光线, 即发出不同的path, 再求平均即可

如果光源很小, 可能要发出很多条path才能碰到光源停止递归
为了解决这个问题, 我们可以在光源上采样



材质与外观(Materials and Appearance)
Material == BRDF, 材质决定了光如何被反射
-
漫反射:
-
出射的radiance是均匀的\(\rightarrow f_r=c(常量)\), 且反射前后irradiance不变
-
由反射方程可以计算出\(f_r=\frac{\rho}{\pi}\)
-

-
光泽材质(Glossy material)

-

-
Ideal reflective / refractive material(BSDF*)
- 同时具有反射和折射, \(BSDF=BRDF+BTDF\)
菲涅尔项:
- 反射率取决于入射角, 和normal法线方向越接近则越少的光被反射
微表面材质(Microfacet Material)
基于如下假设:离得足够远的时候,微小的东西往往看不见,看见的是最后汇聚起来总体的样子, 即远处看材质, 近处看几何

- F: 菲涅尔项, 确定有多少能量将会被反射
- G: 修正微表面可能会互相遮挡的情况, 如正面看球, 球的边缘部分
- D: 微表面法线的分布情况, 分布得比较集中则镜面, 分布得分散则磨砂(h是半程向量)
再谈BRDF
各向同性: BRDF在不同的方位角保持一致
各向异性: 方位角不一样时,BRDF不保持一致(这里所说的方位角是指相对方位角)

BRDF的属性:
- 非负
- 线性可加
- 可逆
- 能量守恒
如何测量BRDF
Motivation:
- Avoid need to develop / derive models 不用费力推模型
- Automatically includes all of the scattering effects present
- Can accurately render with real-world materials
- Useful for product design, special effects, ...
- 实际和推算出来的经常会有很大差距
颜色和感知(color and perception)
光场(Light Field / Lumigraph)
透镜成像:三维物体到二位平面的投影。
三维到二维的投影,会损失一个维度的信息,这个维度常称为深度轴。实际上相机捕获的是场景空间中光线的辐照度信息。那么光线的方向信息也会丢失,也就失去了深度信息。
即,光学透镜成像对三维场景压缩、投影:
- 光线方向信息丢失
- 场景的深度信息丢失
为了解决上面的问题, 我们可以使用光场成像
-
光场:是记录了空间中光线的集合,包含光线在空间中的位置和角度信息。
-
光场的发展可以描述如下:
-
Adelson EH等用七维全光函数\(P(\theta,\phi,\lambda,t,V_X,V_Y,V_Z)\)描述了空间中的光场,七维全光函数过于复杂、数据量大,难以记录以及存储。需要对其进行简化处理。McMillan L 等将维度降到了五维\(P(x,y,z,\theta, \phi)\),通过记录RGB来简化波长 ,通过记录不同帧以简化时间 t。五维光场还可以被进一步简化,进而发展出适用于光学系统的光场双平面参数化表征,即四参数光场\(P(u,v,s,t)\)。假设一条光线在两个不共面的平面(\(u,v\))和平面(\(s,t\))各有一个交点,则该光线可以用这两个交点唯一表示。Ng R 引入图像的坐标 (\(x,y\)) ,形成四参数光场 \(P(u,v,x,y)\) 表示形式。双平面四参数光场可以表示成像所需要的所有光线,因此光场的理论研究和成像系统的设计大多数都以光场双平面模型为基础展开。
-
全光函数: 我们能看到的所有东西\(P(\theta,\phi,\lambda,t,V_X,V_Y,V_Z)\)
- \(\theta,\phi\): 对应球面极坐标下的\(\theta,\phi\), 共同表示一个球面
- \(\lambda\): 光的波长, 反映了颜色
- \(t\): 时间
-
\(V_X,V_Y,V_Z\): 观察的位置
-
最大的优势是可以先拍照再调整参数 :

颜色
SPD(Spectral Power Distribution 光谱功率分布)
-

-
具有线性可加性
颜色是人的一种感知(perception)而不是光的固有属性, 光线投射到人的眼睛里, 经过人眼里的三种对不同波长的光敏感的细胞, 分别将三个属性值(S, M, L)返回大脑, 人脑才能知道光线
- 那么, 有没有一种可能是人脑处理不同的光线得到相同的(S, M, L)呢? 答案是有可能, 这就叫做同色异谱现象
- 意义: 可以用不同的光谱表现物体, 只要能骗过人的眼睛
颜色如何混合?
- 计算机里常用"加色系统": 即RGB可加
- 然而由于RGB三种颜色是三种固定的波长, 那么光谱也只有固定的三根线, 无法形成自然界那种连续的光谱, 这就导致了有一些颜色无法显示, 为此, 我们引入CIE RGB, 即使用一个匹配函数来辅助生成颜色

颜色空间
不太懂, 以后懂了再补上

动画(Animation)
关键帧
影响动画整体走向的帧, 中间的称为过渡帧, 可以通过计算生成过渡帧(通过插值)

物理模拟
只要能够正确建立物理模型,一定可以得出正确的物理模拟结果。
质点弹簧系统
- 理想化弹簧:

- 正常有长度的弹簧

- 引入阻尼

弹簧结构: 不同弹簧的组合,会有不同的性质,可以模拟不同的物品。
布料模拟推导过程
| 序号 | 结构 | 说明 |
|---|---|---|
| 0 |  |
不能模拟布料,因为它不具备布的特性(不能抵抗切力、不能抵抗对折力(布料多少有点抵抗对折的能力,因为它不能像纸一样被折叠)) |
| 1 |  |
改进了一点,虽然能抵抗图示对角线的切力,但是存在各向异性。依然不能抵抗折叠。 |
| 2 |  |
可以抵抗切力,有各向同性,不抗对折 |
| 3 |  |
红色skip connection,注意红线的力比较小。现在可以比较好的模拟布料 |
粒子系统
- 建模一堆微小粒子,定义每个粒子会受到的力(粒子之间的力、来自外部的力、碰撞等)
- 在游戏和图形学中非常流行,很好理解、实现
最简单的实现算法
- 动画的每一帧
- 创建新的粒子(如果需要)
- 计算每个粒子的受力
- 更新每个粒子的位置和速度
- 结束某些粒子生命(如果需要)
- 渲染
运动学
可以粗分为正向运动学和逆运动学
- 正向运动学: 只要定义好骨骼连接方式, 知道角度即可计算出点的位置
- 逆运动学: 创作者只需要调整点的位置, 自动计算出旋转角度, 优点是不用计算复杂的物理, 缺点是解不唯一
动画绑定(Rigging)
某种程度上说是逆运动学的应用, 有点像提线木偶, 捏脸?

动作捕捉(motion capture)
既然可以通过点控制动画, 那么我可以捕捉人的实际动作, 并反映到动画里
优点:
- 快速获得大量真实数据
- 非常真实 缺点
- 昂贵、准备工作麻烦
- 捕捉的动画跟预期艺术需要不太符合,需要调整
- 控制点被遮挡问题
单粒子模拟
学习单个粒子的运动,之后再推广到多粒子系统
- 假设粒子的运动由速度矢量场决定,速度场是关于位置和时间的函数:v(x, t)
- 速度场:定义质点在任何时刻在场中任何位置的速度。给个位置和时间,就能知道速度
- 如下图,箭头方向是速度方向,曲线是粒子在这个速度场中的运动轨迹(粒子0时刻位置知道,以后每个时刻速度都根据速度场进行变化,由于速度变化,位置也会跟随时间产生变化,从而形成的轨迹)

常微分方程
已知速度,建立方程,解常微分方程就可以得到位置量

欧拉方法
- 用上一时刻的信息推导这一时刻的信息(显式欧拉/前向欧拉)
- 用下一时刻的信息推导这一时刻的信息(隐式欧拉/后向欧拉)
- 很常用、非常不准确、非常不稳定

可以用什么方法消除不稳定性?
- 中点方法
- 自适应步长
- 龙格库塔方法(Runge-Kutta)
刚体模拟
模拟刚体很简单
- 刚体不会发生形变
- 类似于粒子系统,刚体相当于内部所有粒子以相同方式运动
- 不同的是刚体的模拟中,会考虑更多的属性
- 有以下属性,可以根据前面提到的欧拉方法或者各种其他稳定性好的方法得出经过Δt以后的位置、角度等信息

流体模拟
通过形成一些小球,通过它们的位置来模拟水和浪花。基于位置的方法不是物理的,没有能量损失,虽然可以人为的加入能量衰减 主要思想
- 水是由一个个刚体小球组成的
- 水不能被压缩
- 任何一个时刻,某个位置的密度发生变化(不同于平静水时该空间的小球的密度),就必须通过移动小球的位置进行密度修正
- 需要知道任何一个位置的密度梯度(这是机器学习的梯度下降)
- gradient descent梯度下降
欧拉 vs 拉格朗日 (Eulerian vs Lagrangian)
拉格朗日方法又叫质点法
欧拉法又叫网格法(和上面解常微分方程的欧拉方法无关)

Mterial Point Method(MPM)
把欧拉法和拉格朗日法混合在一起
- 拉格朗日法:考虑每个粒子都带有一些材质属性
- 欧拉法:用网格做数值积分处理
- 混合:粒子把属性传给网格,网格计算处理更新后返还给粒子